
Consider the plight of a time series econometrician who wants to do a quick and dirty forecast for the next year, conditioned only on past information on GDP. One might end up with series in the graph below.
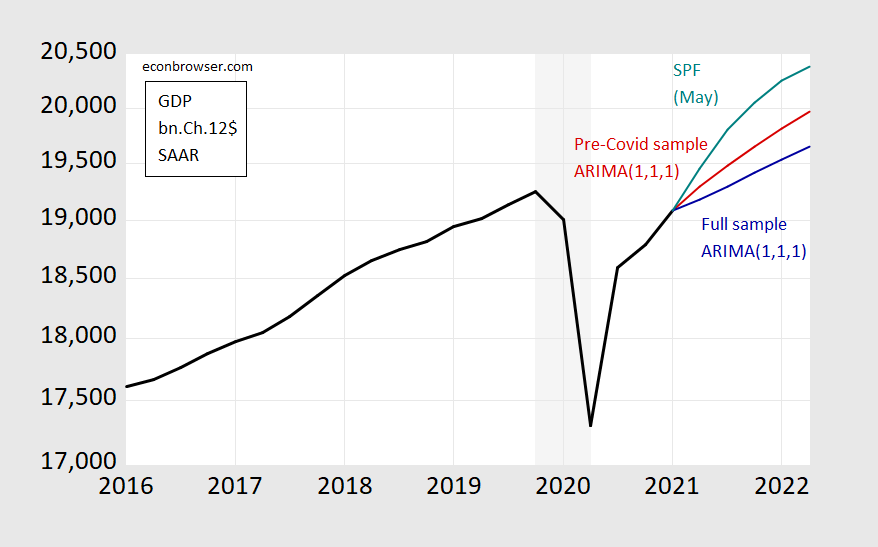
Figure 1: GDP as reported (black), median forecast from Survey of Professional Forecasters (teal), ARIMA(1,1,1) forecast using data 1986-2019Q4 (red), ARIMA(1,1,1) forecast using data 1986-2021Q1 (teal), all in billions of Ch.2012$ SAAR. Light gray shading denotes NBER recession dates assuming trough is at 2020Q2. Source: BEA, SPF, NBER, and author’s calculations.
One’s initial inclination is to use all the available information up to the most recent data (for 2021Q1) to estimate the relationships and to forecast. This leads to the blue line, where I use a simple time series model (ARIMA(1,1,1)), which traditionally has worked not altogether badly in a univariate context. Or, I could use the data available up to before the Covid-19 pandemic to estimate the relationships of interest. That leads to the red line.
Actual forecasters as surveyed by the Philadelphia Fed (teal line) project something different from both – but presumably they are doing something yet different from either. But in their case, they still have to confront the problems of what data to use (in addition to lagged output), what restrictions to impose on the model (Jim discusses these two issues in this post), what conditions to impose (will the infrastructure plan pass, will new Covid-19 variants spread and how far?), what additional variables to use (like big data, higher frequency data, etc.).
Paul Ho at the Richmond Fed summarizes some of the lessons learned in this period of forecasting in unprecedented times, in a much more sophisticated and comprehensive framework.
How Forecasters Adjusted to the New Environment
Faced with unique circumstances, forecasters had to acknowledge the difference without completely ignoring lessons from previous business cycles:
Should one view the COVID-19 pandemic as simply a period of high volatility?
Would economic variables comove differently than previous recessions?
Would the effects of the pandemic propagate and persist as other drivers of business cycles do?
These questions mattered for forecasts but did not have precise answers with the scarce amount of data available, especially in the early stages of the pandemic. How could forecasters tackle such questions as the pandemic unfolded, acknowledge the level of confidence in their answers and express how these questions influence their point forecasts and associated uncertainty?In a recent working paper, “Forecasting in the Absence of Precedent,” I discuss two broad approaches to dealing with the lack of precedent. First, forecasters used subjective judgment or prior knowledge — typically from economic theory — to adapt their models. Such model adjustments are most fruitful when their underlying assumptions are transparent and acknowledge the lack of certainty.
Alternatively, forecasters found new sources of information, typically by incorporating new data into forecasting models. For example, epidemiological and high-frequency data were of special interest during the pandemic. However, forecasters need to know how these new variables comove with variables of interest, which once more raises the question of model specification and the choice of assumptions. This Economic Brief focuses on several representative papers for each approach.
Note that forecasting is a separate (albeit related) enterprise from nowcasting. On the latter, in the context of the Covid-19 recession, see Econbrowser posts here and here. Some weekly indicators discussed here (OECD). Jim discussed the NY Fed and Atlanta Fed nowcast methodologies (pre-Covid-19) here.


Comments
Log in or sign up to join the conversation.