
Predicting the Future, One Day at a Time
- Volatility forecasting can work reasonably well—but measuring results is not as easy as it appears.
- Estimation methods have evolved from the 1980s through today as access to more data increased.
- Capturing both intraday and overnight moves is important for proper risk management.
- More sophisticated methods that place more weight on more recent observations tend to outperform.
- Adding high frequency returns can significantly improve forecast accuracy using relatively simple methods.
Maintaining an accurate view on volatility is a critical task in investing. Keeping tabs on market gyrations is not a perfect measure of risk—we care more about volatility on the downside than up. But volatility is a useful gauge for judging how much pain an investor is willing to tolerate or how assets can be combined in ways to diversify a portfolio to maximize risk-adjusted returns.
Although compounding returns over time may be the goal, market volatility can strike quickly in a matter of days with even the most seasoned investors jarred by sudden shocks to their portfolio. Having an effective means of estimating day-to-day risk can help better prepare for volatility when it does arise and act smarter in response.
Measuring, forecasting, and interpreting volatility is another matter. There are very smart people with advanced degrees and training that specialize in the modeling of volatility and how it gets used in pricing derivatives or managing risk. But there are some basic principles and even advanced techniques that can be used by a wider range of market participants that can help improve their knowledge.
The purpose of this guide is two-fold. The first is to clearly explain some of the foundational principles and different methods of forecasting volatility for practical use. While we attempt to keep the mix of Greek letters and inscrutable squiggles down to a minimum, the target audience is the generally informed, sophisticated investor or market professional.1 The goal is not to “dumb it down”—only make it more accessible. We take the time to explain key elements and provide additional detail in the footnotes that might be second nature to a quant but could serve as a refresher to those with limited day to day exposure to some of these concepts and methods.2
The second is to highlight the efficacy of using higher frequency data to help improve accuracy and responsiveness in forecasting volatility. Although this uses many more data points in the process, even relatively simple methods leveraging high frequency data tend to perform as well or better than more complicated modeling techniques. We aim to demonstrate how powerful forecasting tools can be constructed using this more granular data along with basic math at the undergraduate level.
We begin with an overview of volatility’s unusual characteristics followed by a brief survey of different measures and techniques that have been developed over the years. Then we compare how accurately these different measures can predict the volatility in the S&P 500 over a very short period—just one day. We conclude by showing how choices of forecasting tools and benchmarks can impact the ranking of these different models for use in practice.
Characteristics of Volatility
Volatility (and its squared cousin, variance, which we will refer to interchangeably throughout) has some unusual properties.
Volatility is not directly observable, even after the fact. We can observe prices and changes that are the result
of volatility, but there is no single value that equates to a “true” value. As a result, we can only estimate volatility over
specific periods of time.3 The inability to precisely measure its true value presents challenges in judging the accuracy of an estimate, even when using multiple benchmarks.
Volatility levels are always changing. It is apparent to any market watcher that volatility is not constant, adding more complexity to the process of modeling its impact. One of the weaknesses of the well-known Black-Scholes model for pricing options is its assumption of constant or deterministic volatility. Like many economic assumptions, this was done for modeling simplicity rather than any real-world expectations. Many modern techniques assume volatility is a stochastic or time varying process (a random walk in a time series), which is more realistic but also more difficult to model.
Estimating volatility has both continuous and discrete elements. Since most assets have set trading sessions with nights, holidays, and weekends, there are both continuous and discrete components that must be modeled somewhat separately and can be tricky to reconcile. Theoretically, volatility is a continuous process even though there may not be prices available to help estimate its level. But that will not be reflected until price forms at the start of the next session, creating a gap or “jump” that must be incorporated into the forecast. Focusing on one component at the expense of the other can lead to mismatches between theory and practice while introducing significant estimation errors.
Volatility tends to be highly autoregressive. Fortunately for market practitioners, volatility experienced over the recent past can be a useful predictor of volatility in the future. In varying over time, volatility also tends to cluster around events and then takes some time to decay back to some normalized level. These properties lend themselves to some reasonably effective methods of forecasting in comparison to predicting returns, which can be much more difficult.
Due to its autoregressive properties, even a simple 10-day historical standard deviation of returns can be useful forecast of tomorrow’s volatility. If annualized volatility over this 10-day span is rather high at 32%, it is very likely tomorrow’s volatility will continue to be high.4 But what are the inputs used to calculate this measure? Like many estimates and forecasts, 10-day historical volatility only looks at the daily, close-to-close price returns. But what about the rest of the day?
It is also highly likely that large variations in the close-to-close price indicating higher volatility will be mirrored in the moves intraday as well. But the collective swings in those relatively small daily returns could be an indication of even bigger day to day swings in the days to come. One of the ways to capture some of this information is by incorporating the daily range (the differences between the open, high, low, and close for the day), which is explored in several of the methods in the next section. But we also delve into using intraday returns themselves, capturing the variation directly in a more continuous process that is closer to the theoretical ideal.
Tools of the Trade
Including all the methods of estimating and forecasting volatility is well beyond the scope of this analysis. But a core range of techniques can be generally organized by their methods, sampling frequencies, and inputs ranging from the very simple to highly sophisticated.
The academic literature often examines estimators more as proxies for the past unobserved latent variance, but many analyze the same tools for use in forecasting. They are highly related but not identical concepts. For our purposes, we focus on how well these measures can predict future short-term volatility by lagging them one day, which obviously needs appropriate proxies to measure results.
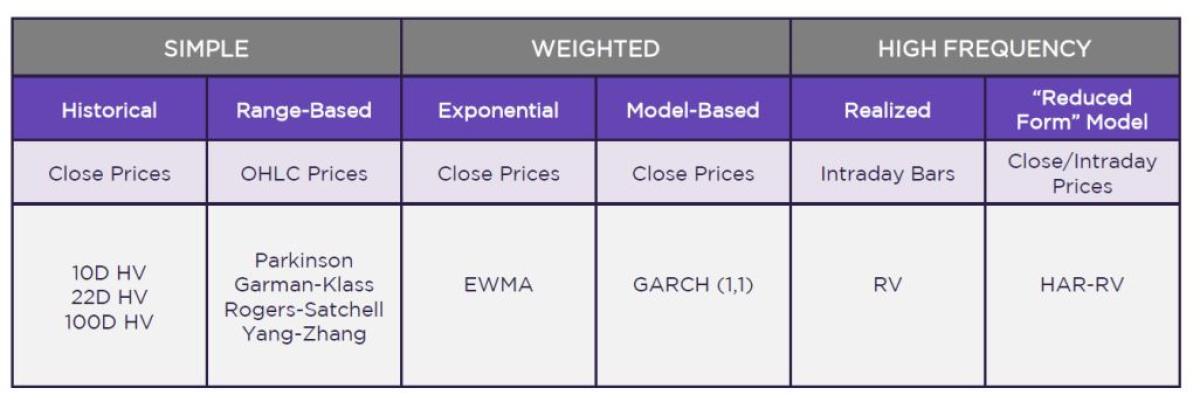
Historical
A basic standard deviation of daily returns over the recent past is a logical starting point to begin measuring volatility. Even those with very sophisticated volatility models will find historical volatility a useful datapoint for comparison. Common lookback periods include 10 days (two weeks accounting for weekends), one month (22 trading days or 30 calendar days), or out a few months or longer (100 or even 252 days).5
Historical volatility may be simple but there are still some assumptions and modifications to be made. For one, we typically use log returns for many volatility calculations, as they are continuously compounded, instead of simple returns.6

We also make some small changes to the standard variance formula7:
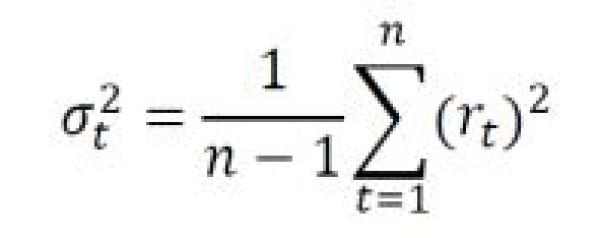
A standard sample variance is calculated by the sum of the squares of the differences between the observations and the sample mean divided by the number of observations minus 1. However, there is one modification we make that differs from standard variance in statistics: we assume the average daily log return (the “drift”) will be zero. This reduces it to the sum of the squares of the daily log returns divided by the number of observations minus one (as shown in the formula above). When looking at relatively short lookback periods such as 10 days, it is possible for average returns to be so extraordinarily high or low, they become unrealistic to annualize and significantly distort the volatility calculation. As a result, it is often simpler to assume zero drift when computing historical volatility.
Easy to calculate and understand, historical volatility does have its limitations. For one, it is entirely backward-looking and makes no attempt to make any adjustments to forecast future volatility. It treats every single day in
the time series equally, giving more distant data points the same ability to influence the outcome even though conditions may have since changed. It also forces the selection of a lookback period, which can be an arbitrary decision with outsized impact. Lastly, the use of just close-to-close price information ignores intraday movements that may provide a more complete picture.
Range-Based
Another class of estimators attempts to address the limitation of only using closing prices by incorporating the daily range into the calculation. Introduced over time from about 1980 to 2000, the methods below build on each other, adding elements that were missing from prior versions to capture more real-world dynamics and improve accuracy.
Parkinson
The earliest range-based estimator, Parkinson uses the range defined by the difference between the low and high of the day instead of closing prices.8
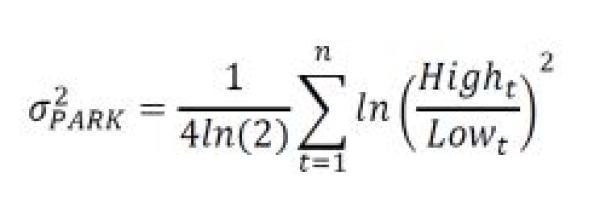
One key limitation is the assumption of continuous trading, as no information from the overnight gap (the prior close to next day’s open or “jump” in academic parlance) is included, which tends to underestimate volatility. Approximately one-fifth of the total daily price variation occurs overnight—a significant portion to be omitted in the estimate.9
Garman-Klass
Extending Parkinson, the Garman-Klass (GK) estimator adds two more range-based measures, the opening and closing prices. If the opening price is unavailable, the model allows for the prior day’s close to be used in place.
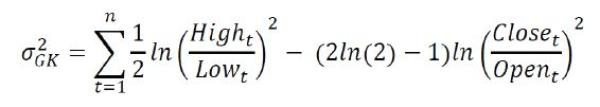
But absent that condition it normally ignores the overnight return so suffers from the same systematic underestimation error as Parkinson.
Rogers-Satchell
Unlike the previous estimators, Rogers-Satchell assumes a non-zero mean return with the same OHLC data points to construct a more sophisticated measure.
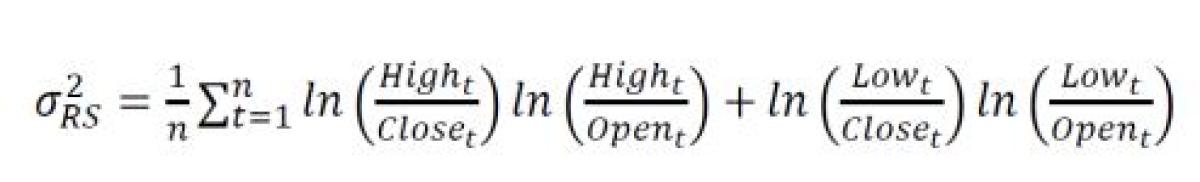
Despite the addition of drift to the model, it still ignores any of the information in the overnight jump, leading thismeasure to also under-estimate full day volatility.
Yang-Zhang
Finally, Yang-Zhang brings together the elements of the prior range-based models and attempts to address all their shortcomings.10 It combines overnight volatility with a weighted average of open to close and Rogers-Satchell volatility.

The measure incorporates the overnight jumps while capturing elements of the trend (assumes non-zero mean return), creating a more robust measure than the other range-based estimators.11 We address additional aspects of weighting overnight versus intraday volatility in a subsequent section on measures using high frequency, intraday returns instead of daily OHLC.
Exponential Weighting
While the Yang-Zhang model manages to address many of the weaknesses in the earlier range-based models, it still has a significant limitation: all the data points in the historical lookback are weighted equally. Given the tendency for volatility to spike and then take some time to fade, placing more weight on more recent observations yet accommodating the residual effects of an event that is still lingering in the market’s memory can help better model real-world conditions. Without some smoothing of the data, a volatility event will abruptly drop off from a moving window of historical data.
One approach is to use exponentially weighted moving average (EWMA) volatility, which applies a decay factor to prior observations to smooth out the series.12
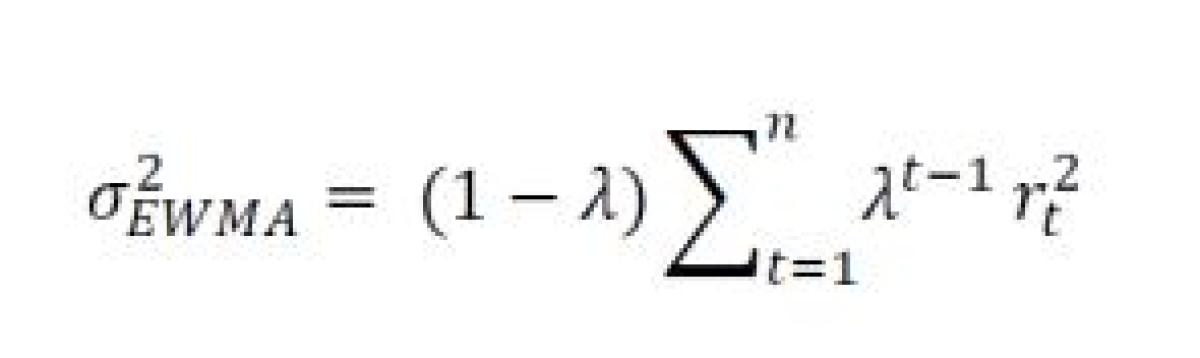
The decay (represented by lambda,) must be a value less than one, typically set to 0.94 for daily data but can be adjusted a little higher (for slower decay) or lower (for faster decay). Using the default value of 0.94, starting at index 1 in the formula above results in a weight of (1-0.94) *(0.94)0 = 6.00% for the most recent day followed by (1- 0.94) * (0.94)1 = 5.64% for day prior, (1-0.94) * (0.94)2 =5.30% for the third prior day and so on.13
The ease of computation and performance of the EWMA estimator makes it a popular choice among practitioners. It is also used for index products such as structured notes and fixed index annuities that seek to target volatility levels with daily rebalancing.14
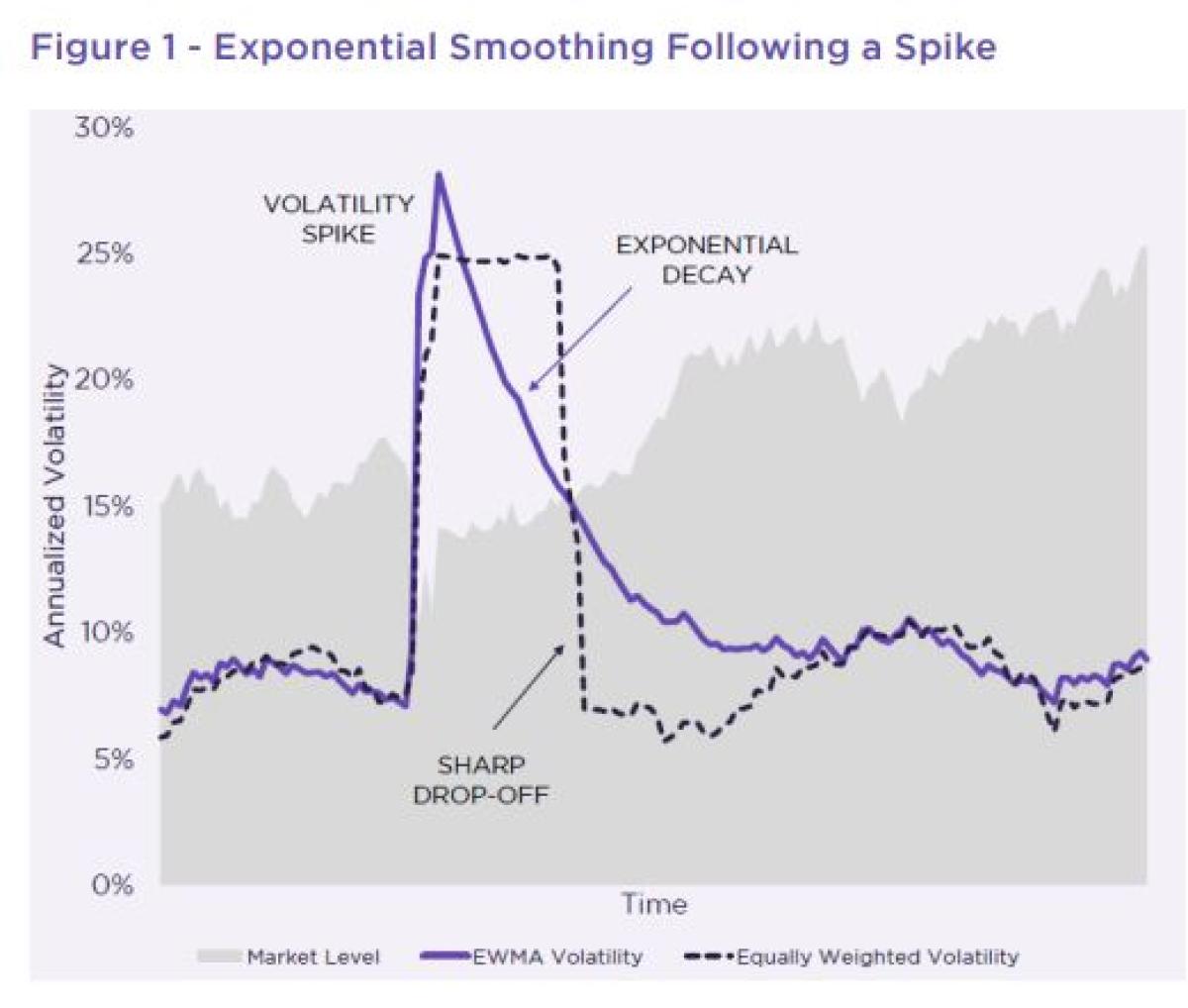
Despite its utility and simplicity as workhorse, EWMA also has its limitations. For one, it only uses daily returns, leaving it susceptible to shocks potentially concealed in large intraday swings that may be a precursor to a larger volatility event. Secondly, it forces you to somewhat arbitrarily select a lambda that can significantly impact the outcome (too fast or too slow). However, using a combination of two or more lambdas can help mitigate this, especially with simple rules that use the higher of the two values (a fast and a slow) to be on the conservative side.
GARCH
GARCH stands for Generalized Autoregressive Conditional Heteroskedasticity¸ and is a parameterized econometric modeling technique that can be used to estimate volatility. The key innovation with this model begins with the last part of the name—heteroskedasticity. In standard linear regression, the assumption is that the error term—the noise that will cause the dependent variable to deviate from its relationship with the independent one—will have a constant variance (homoscedasticity). With GARCH, the assumption is the variance of the error term will be time-varying but is also conditional on the overall level of variance. Cutting through a lot of the jargon, a GARCH process is well-matched to the clustering behavior and persistence of volatility following certain events in the market. But with these more realistic assumptions come more complicated techniques to manage those conditions. GARCH was developed in 1986 by Tim Bollerslev following the work of Robert Engle who introduced the “ARCH” part in 1982.15 The most commonly used GARCH (1,1) model can be specified as follows16:
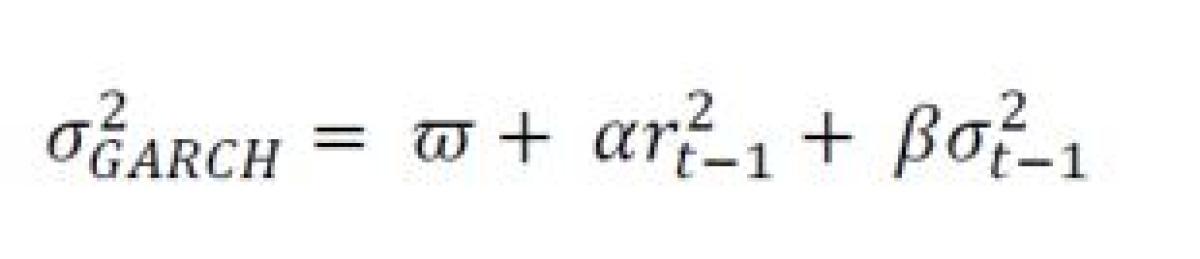
There is a lot to unpack in this relatively simple equation, but we begin with a plain English description of what themodel is doing. Paraphra sing Engle, GARCH is a weighted average of the long run variance, the predicted variance, and the variance of the most recent squared residual, which correspond to the terms in the equation above in that order.17
To fit the model, the constants 'w', alpha and beta must be estimated and have some constraints.18 Getting these parameters involves using maximum likelihood estimation, a statistical technique designed to find the values with the highest probability that the process in the model produced the observed data.19 Once fit, a variety of tests for significance are performed to confirm the model is correctly specified.20 Once specified, GARCH produces an entire time series of variance forecasts, easily updating with just the prior prediction and residual.
While somewhat complex, GARCH is a very powerful tool and tends to perform well in forecasting. While not immediately apparent from the description of the process, the GARCH formula places more weight on the
more recent data, similar to the previously described exponentially weighted volatility. In fact, EWMA is a special case of GARCH (1,1)—and GARCH (1,1) is a generalized form of EWMA.21 What EWMA lacks is the “long memory” in GARCH that assumes reversion to some long-term mean level of variance over time. GARCH is not computationally difficult and open-source tools in Python and other platforms make it easier to manage with access to price data and some programming skill. It is widely used for tasks such as managing portfolio risk or pricing derivatives. However, it is not without drawbacks.
One is that the basic GARCH (1,1) assumes that positive or negative shocks have an equal impact on volatility when in reality there is a strong negative relationship between returns and volatility, commonly referred to as the leverage effect.22 There have been a whole family of GARCH-based variants (EGARCH, FIGARCH, GJRGARCH, and others) developed to address asymmetry and add other features to the process, but they come at a cost of higher complexity and difficulty in fitting the model. More importantly, most GARCH models still generally use only daily closing prices, leaving them vulnerable to more sudden volatility shocks that could potentially be detected with higher-frequency intraday returns.
Realized Volatility
The use of high-frequency returns in modeling volatility has increased with the wider availability of intraday data by both practitioners and academics alike over the last 20 years. Known as realized volatility (“RV”)23, it traces its intellectual roots back to a paper by Robert Merton from 1980, who concluded that volatility could be more precisely estimated from realized returns that improve with higher sampling frequencies.24 The realized variance for a single day is simply the sum of squared intraday returns:
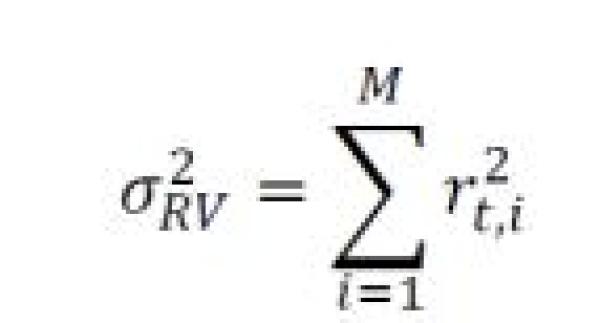
The sampling frequency used generally ranges from 5 to 30 minutes, with the “M” in the formula above corresponding to the number of bars that constitute a full day (78 for 5-minute bars in a 6.5-hour US trading day
from 9:30AM-4PM).25 As with some of the earlier historical estimators, there is no “drift” or mean return subtracted from each squared return as the assumed return from intraday returns is even closer to zero than daily.
As a forecasting tool, RV suffers from some of the same limitations as some of the earlier range-based estimators. Without the overnight return, an RV-only estimator will tend to underestimate the total variation that is important to a practitioner. The overnight gap plus the variability during the day are both metrics that matter for a position or hedge and would be measured by a real-time risk management system.
In the next section, we focus on RV as a building block of more sophisticated forecasting techniques. But for completeness, we also evaluate its efficacy as a forecast tool itself alongside the other estimators.
HAR-RV
Introduced by Fulvio Corsi, the Heterogeneous Autoregressive Realized Volatility (HAR-RV) model has a relatively simple structure featuring three main drivers.26 The first is the use of daily RV—the same measure defined above that sums the squares of intraday returns for the day at a fixed interval such as 5 minutes. This adds the rich information available from higher frequency data, sampled at a low enough frequency to avoid distortion from market microstructure noise. Secondly, it uses a cascading series of lagged terms that are designed to capture the actions of market participants with differing time horizons in their investment process.27 Lastly, it uses simple linear regression (OLS) to estimate its three coefficients, capturing some longer-term historical patterns across multiple market regimes. This component mimics, but does not completely replicate, the “long memory” feature of GARCH.
The model in its simplest form can be specified as follows:
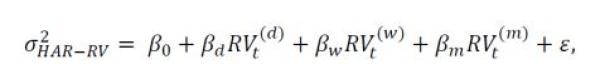
where RV(d), RV(w), and RV (m) represent realized variance (squared terms) for a one-day, one-week (5 day), and one month (22 day) period on day t.28 To get the multi-day measure, the “building block” of a single day’s RV is simply averaged over the desired period (e.g. sum up the RV for 5 days and divide by 5).
Estimating the coefficients involves initializing the model at a point in the past using as much historical data as possible. However, for a more robust and practical implementation, we use an expanding window—only letting the model use as much information that existed up to the point of the forecast date. This “walk-forward” approach helps avoid look-ahead bias and reduces the potential for overfitting the model.29
HAR-RV tends to perform very well against the more complex GARCH and is easier to fit. It possesses some of the mean-reverting properties of GARCH and places more weight on recent observations while capturing the dynamics of intraday price action for improved response to volatility shocks. Like GARCH, HAR-RV has spawned a number of extensions, focusing on correcting for asymmetry (using semi-variance in SHAR) or dynamically adjusting RV due to inherent measurement error (“integrated quarticity” in Bollerslev’s HARQ). But the biggest item to address is the glaring weakness in an RV-only estimator—the lack of any contribution from the overnight jump.
Without addressing the jump, HAR-based models will tend to underestimate volatility in comparison to methods like EWMA or GARCH that capture this information. A HAR-based model may be very effective in forecasting the RV for a single day, but the overnight return represents risk to practitioners that cannot be ignored even if RV is a “better” representation of the integrated, unobservable variance.
Bollerslev added a jump term to the basic model with his HAR-J, simply folding in the previous day’s overnight return as another term in the regression. Others decompose the jump into separate components matching the 1-, 5-, 22-day lags in the RV terms. More recently, Bollerslev concluded that simply adding the squared overnight return to the sum in calculating RV itself can be a more effective means of adding the information.30 However, we find an alternative approach performs even better: scaling the RV-based forecast up o better approximate a measure using daily data.
As referenced before, Hansen and Lunde (2005) estimate that overnight returns contribute about one-fifth of the daily price variation based on their historical analysis of Dow Jones Industrial Average stocks. In their paper that has been extensively referenced and replicated, they propose three ways to combine RV with overnight returns to get an equivalent variance for the entire day.31 The paper primarily focuses on the problem of getting the best estimator of integrated variance, but we use similar techniques to adjust HAR-RV-based forecasts to daily equivalents.
The first is to simply multiply the RV-based measure by a static scalar representing the average contribution from the overnight return. Using Hansen and Lunde’s estimate of one-fifth, this translates to a scalar of 1.25x (squared for variance).32 This static scalar can perform well, especially for broad market indices, but can be improved with a more dynamic approach. The second method just adds the overnight return to the RV measure as Bollerslev suggests. But Hansen and Lunde argue this method adds a very noisy measure to the estimate, potentially distorting the result.
The last method involves an optimized weighting of the overnight and RV components that helps smooth out some of the noisiness in just adding the overnight return. The weighting method is complex and beyond the scope of this paper to go through in any detail but has been well-supported by subsequent research since its initial publication.33 We combine this optimization process with the HAR-RV in forming our preferred forecast detailed in the next section.

Comparing Forecast Accuracy
Now that we have defined a general set of estimators and forecasting methods ranging from basic to advanced, we
compared the predictive power of each along with their pros and cons. For our test, we analyzed the ability of each
estimator to forecast volatility one day ahead using a variety of proxies as benchmarks.
Data
As a proxy for US equity market volatility, we used returns from the SPDR S&P 500 ETF (SPY), with data from January 1, 1997 through December 31, 2020. We sourced open, high, low, and closing prices from Bloomberg and intraday 15-minute bars from Cboe’s Livevol Datashop.
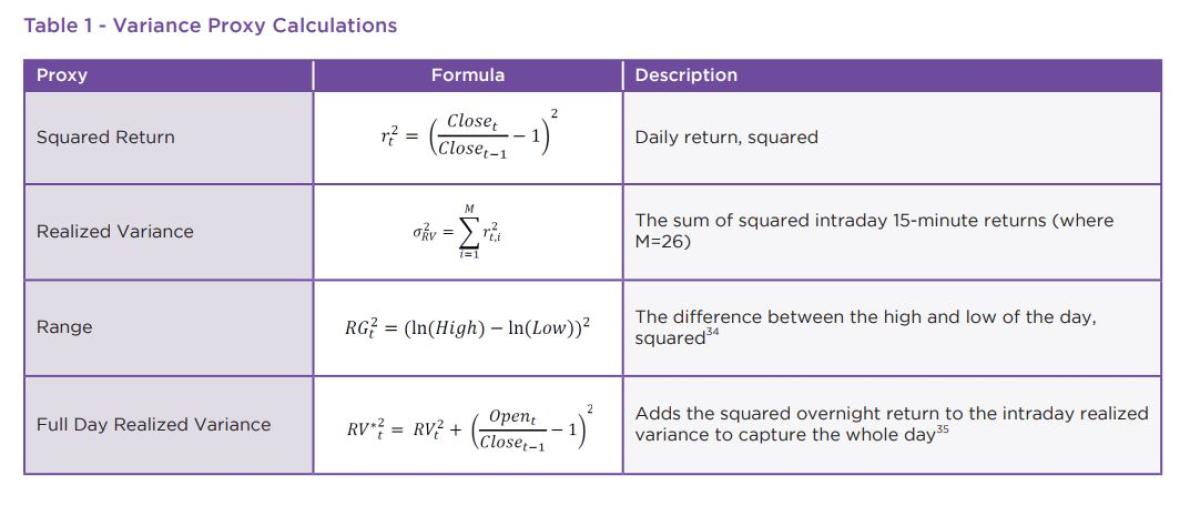
Variance Proxies
Since true volatility is unobservable, selecting more than one proxy is advisable. To avoid biasing conclusions towards the more intraday-focused realized measures versus less frequent sampling using daily data, we used a range of both as proxies for all estimators.
Loss Functions
In addition to benchmarks to measure against, the tools used to measure the errors from the predictions are equally
as important. Like with the proxies, we used a range of loss functions36 to provide more context. In the formulas in the following table, sigma-hat-squared represents the model-estimated value and the h represents the (true) variance proxy.
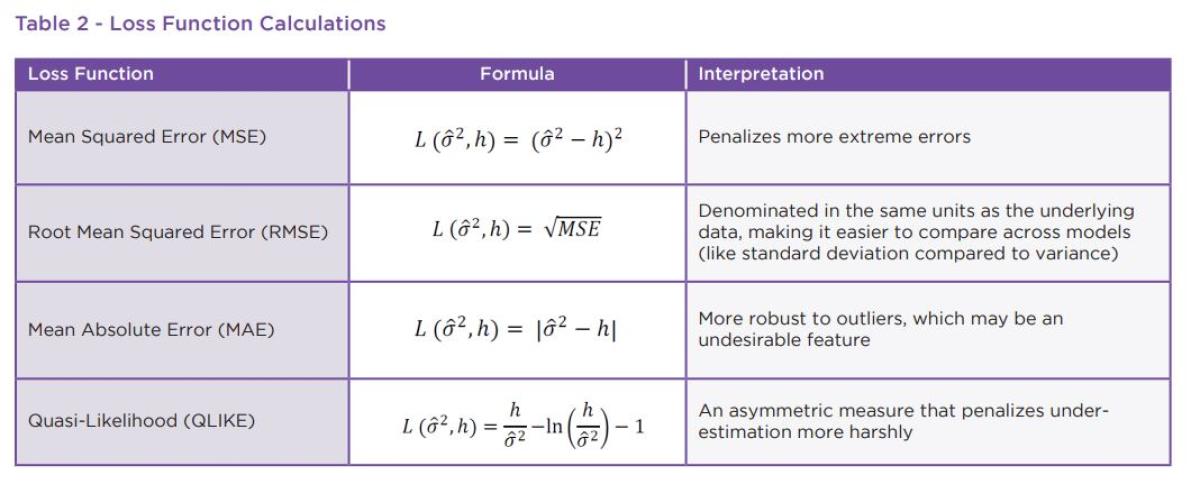
Use of the “wrong” loss function can lead to some significant errors in ranking the efficacy of the forecasts. In prior work on volatility forecasting, MSE and QLIKE are shown to be more robust to noise in the proxy, making them generally preferred in terms of ranking.37 While we focus on these two robust measures in our analysis, we include the other loss functions to highlight strengths and weaknesses of the estimators and show how their rankings can be distorted.
Forecast Methods
We use all the estimators presented in this paper for a comprehensive comparison. For measures that require a historical lookback, we specified short (10 day), medium (22 day), and long (100 day) periods and calculated a set of results for each.
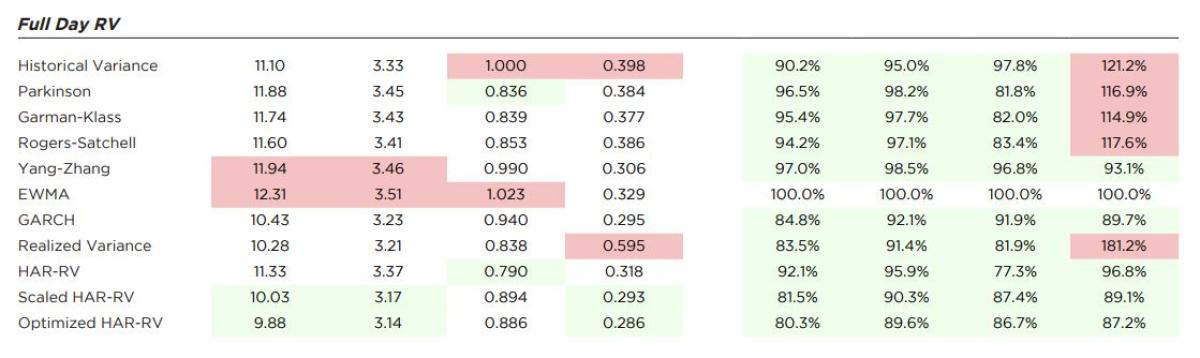
Results Overview
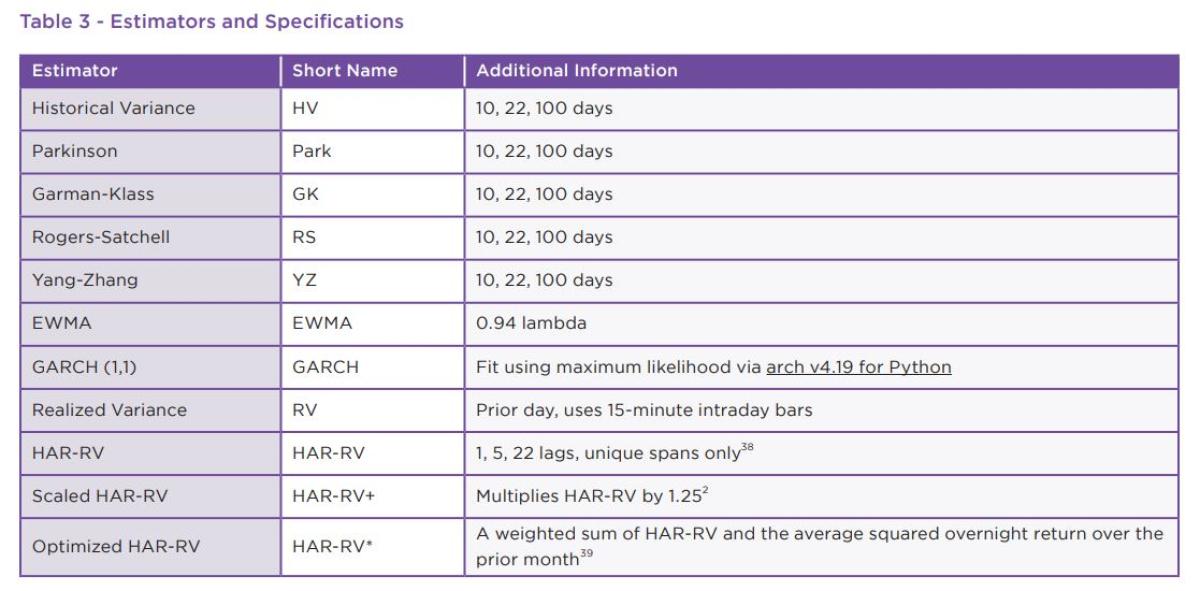
In Exhibit 1, we ranked all estimators by their forecasting performance against each proxy, focusing on the two robust loss functions, MSE and QLIKE. We limited analysis to the 10-day lookback period for all estimators that require one as they clearly outperformed the longer term 22-day and 100-day lookbacks across all metrics by an overwhelming margin.
Despite being considered a noisy proxy, Squared Return in Panel A in Exhibit 1 provides some initial insights into the strengths and weaknesses of each estimator. The realized variance measures (RV, HAR-RV*, HAR-RV+) performed best against MSE, but RV itself drops to the bottom using QLIKE. Since Squared Return includes the overnight jump, the intraday-only RV is penalized more for its under-estimation. EWMA performed relatively poorly against MSE but was much better using QLIKE, helped by its inclusion of the overnight return in its calculation and higher weighting of more recent observations. GARCH, and the three HAR variants are all consistently strong against both loss functions.
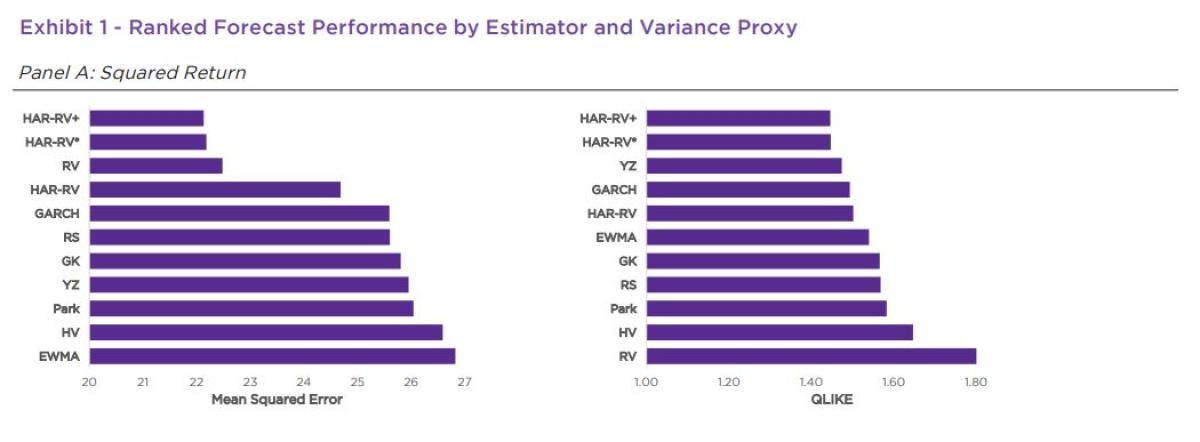
Since Realized Variance removes the overnight component, it should be no surprise that RV, HAR-RV, and the range-based estimators without a jump component performed relatively better in Panel B. The relatively poor performance of standard industry methods GARCH and EWMA against QLIKE suggests that Realized Variance is not well-aligned with practice as a benchmark, as both are widely used in real-world applications. And the addition of an overnight component to HAR-RV+ and HAR-RV* is designed to make them equivalent to measures like GARCH and EWMA.
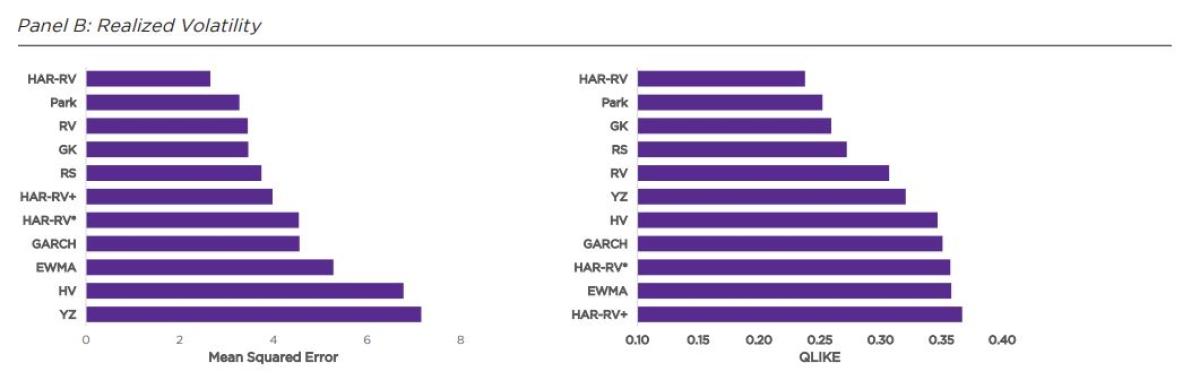
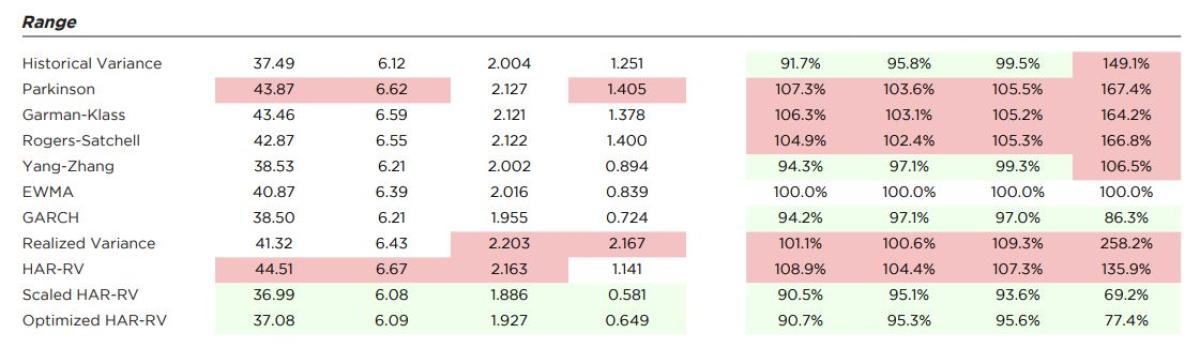
Panel C shows that despite their name, the range-based estimators (Parkinson, Garman-Klass, Rogers-Satchell) except for Yang-Zhang were relatively poor predictors of the Range. The more sophisticated models performed well, especially against QLIKE, with the weighting of more recent results helping EWMA and GARCH guard against under-estimation. HAR-RV* and HAR-RV+ also place more weight on recent results, but also capture intraday variation which apparently leads to some value in forecasting the daily range.
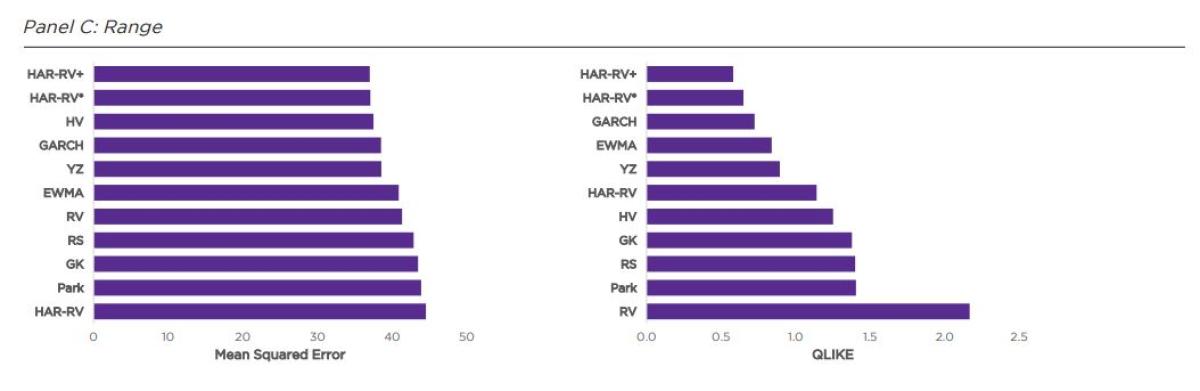
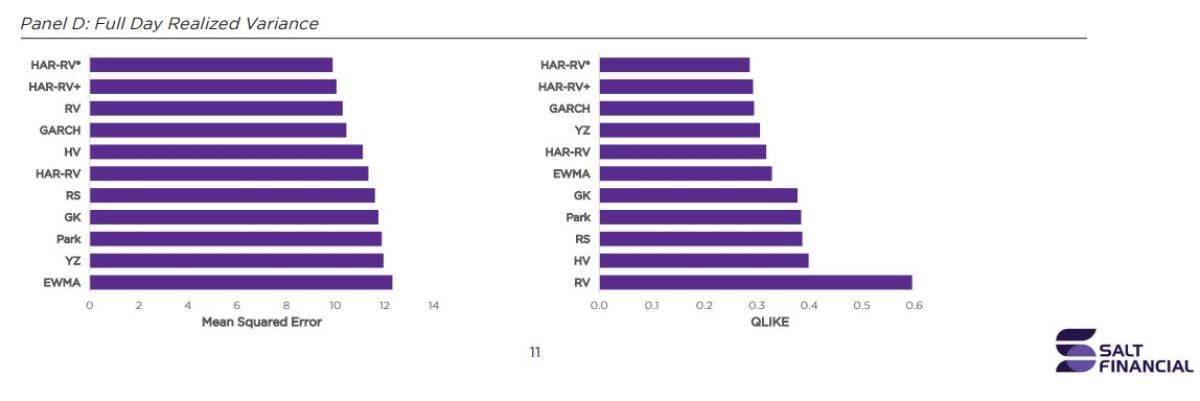
Lastly, using the full range of intraday and overnight variation as a proxy in Panel D, the more sophisticated estimators that either directly capture or model both components perform well whereas the range-based
(Parkinson, Garman-Klass, Rogers-Satchell) and more naïve ones (RV, HV) performed poorly, especially RV against QLIKE.
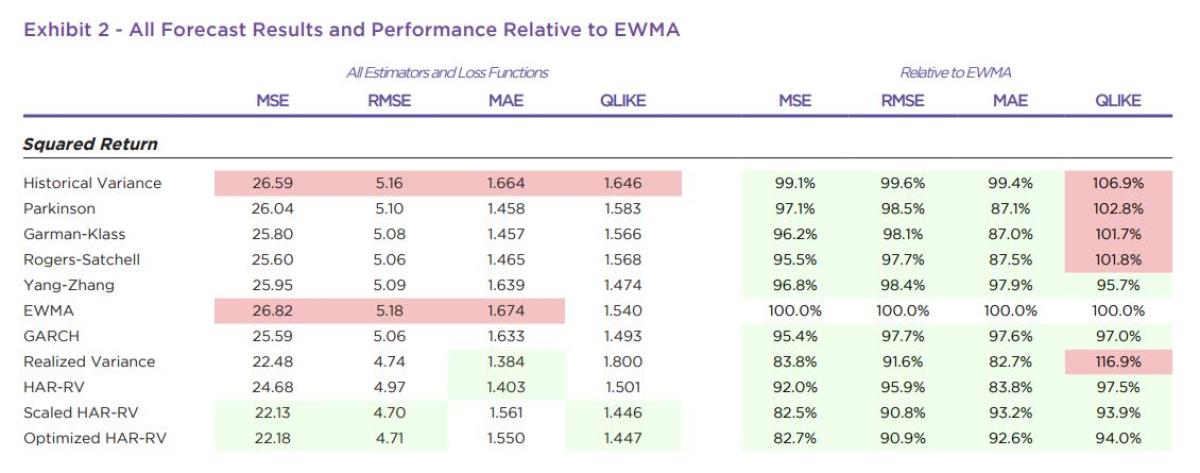
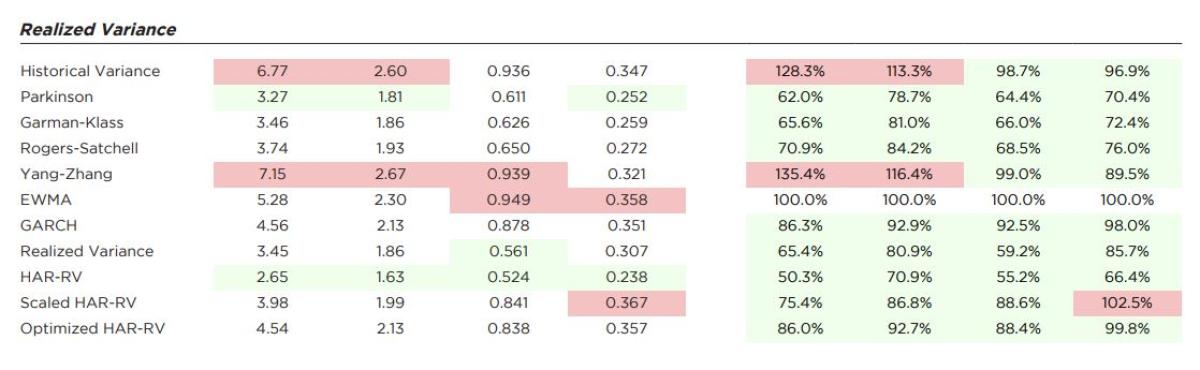
Exhibit 2 shows the full range of values by variance proxy for each estimator against all four loss functions. The top two most accurate estimators in each column for each proxy are colored in green and the least accurate two in red. To the right of the performance against each proxy, we also report performance of all estimators benchmarked relative to EWMA, a standard estimator with wide application throughout the financial industry. All values below one (more accurate than EWMA) are colored green whereas values greater than one (less accurate than EWMA) are colored red
Focusing on the results relative to EWMA highlights some broad differences in how these estimators work. The HAR models and GARCH are clustered fairly closely to EWMA across the range of variance proxies, owing to their inclusion of jump returns and weighting of more recent values.
The output for QLIKE and MSE (and indirectly RMSE as it is just the square root of MSE) aligns with the rankings in Exhibit 1. But looking at the other metrics such as MAE is quite instructive as it demonstrates the importance of using the correct loss function for the task. Estimators like RV or HAR-RV that use intraday data and exclude the jump component look strong compared to EWMA, GARCH, HAR-RV*, or HAR-RV+ when measured against a Squared Return proxy and MAE. But when factoring in the risk of under-estimation, HAR-RV slips and RV falls to the worst ranked estimator in using QLIKE to evaluate.
Across the loss functions and multiple proxies, the realized volatility estimators that adjust for overnight returns—Scaled HAR-RV (HAR-RV+) and Optimized HARRV (HAR-RV*)—are consistently top performers. While measuring against the combination of intraday squared returns and the squared overnight gap might seem tailormade for these estimators, their strong performance against all the proxies further supports their case as very effective forecasting tools. And while not showing up in the top two for any column, EWMA and especially GARCH also performed very well, reflective of their traditional and continued use by practitioners. The more naïve early estimators based on historical standard deviation or daily range are simply less effective, only scoring well against a limited combination of proxy and loss functions.
\
Conclusion
The wider availability of intraday data over the last twenty years has encouraged more research into its use for volatility forecasting. But while realized volatility is used in practice among quantitatively-oriented
asset managers, investment banks, and other financial institutions, anecdotally EWMA and GARCH are still more prevalent in practice. For specialized volatility-targeted products such as risk control indices used in structured products or fixed index annuities, EWMA-based forecasts for targeting are clearly dominant (although different models are used to help hedge their exposure).
For portfolio risk management and derivatives pricing, more sophisticated variants of GARCH are widely in use, which may perform significantly better than the standard GARCH (1,1) presented here. There are also some GARCH models that use realized volatility components, adding
the increased responsiveness of intraday data to improve their forecasts. But they come at the cost of increased complexity in fitting and maintaining these models. For accuracy, responsiveness, and ease of calculation, it is difficult to beat some of the HAR-based estimators that are properly tuned for the full day’s volatility.
While the basic HAR-RV has been in use for over a decade, there are still ongoing efforts to improve its forecasting accuracy using the same basic structure. Bollerslev, who initially developed GARCH, has been
primarily focused on research using realized volatility and HAR-based models in recent years. The fine-tuning of the continuous intraday and overnight components into an estimate that best captures the desired risk characteristics for a given day is of critical importance. While the realized variance may be an unbiased proxy for the latent integrated variance, it fails to account for all the practical risks that a professional with capital at risk faces. A sharp loss at the opening of trading in a volatile market that is exacerbated by an inferior risk model is a threat to one’s P&L and potentially their job. In our opinion, the impact of the overnight return plus the variation experienced throughout the trading session is most aligned with the practitioner and the best proxy for volatility. As a result, a risk forecast that explicitly accounts for these components with solid performance across a range of variance proxies such as HAR-RV+ or HAR-RV* is very well suited for practical application in day-to-day risk management applications.
As stated previously, covering all forms of volatility forecasting in a relatively brief overview would be impossible. In addition to many variants in the GARCH family of models, there are other methods we do not even mention (the Heston model, Markov chains, Monte Carlo simulations, and other stochastic volatility models). Market-derived inputs such as option implied volatility or VIX are another form of forward-looking measure that can be used to help predict future volatility.
Regardless of the tools and methods used, we believe that higher frequency data will continue to be an evolving part of volatility forecasting and risk management for years to come. Intuitively, having more frequent sampling of data should lead to more accurate results. If asked to forecast tomorrow’s temperature at 3pm, would you rather use the seasonal average, the average over the last two weeks, or the hourly temperature over the last 48 hours? With the low cost of computing power and data storage compared to even ten years ago, we expect the future of forecasting will harness this data for even more sophisticated techniques, especially where they tend to be most effective in the short-term.
Footnotes:









More By This Author:
The Surprising Reason It Might Be OK To Give In To Greed And Fear
10 Reasons Why Marinas Are Great Alternative Investments
Skis & Bikes: The Untold Story Of Diversification



Comments
Log in or sign up to join the conversation.